WikiData Real-Time Analytics Platform
End-to-end streaming pipeline on Databricks with enrichment, curated Delta tables, and a live analytics dashboard — demonstrating enterprise-scale cloud engineering skills for the Senior Cloud Services Engineer role.
Portfolio Showcase: Live implementation with active Databricks workspace, real-time dashboards, and enterprise platform access — ready for technical discussion.
Project Overview
Built a real-time data engineering pipeline that streams live WikiData changes, enriches them with metadata via the WikiData API, lands data into Delta Lake tables, and powers analytics with SQL dashboards — all on Databricks.
- Streaming ingestion from WikiMedia EventStreams
- PySpark + Pandas UDF enrichment and caching
- Curated Delta tables for query performance
- Real-time dashboard: top entities, bot vs human, types
Live Implementation Proof
Active Databricks Development Environment
Live Databricks workspace with ingestion notebooks, curation scripts, and dashboard queries(Click to enlarge)
Real-Time Analytics Dashboard
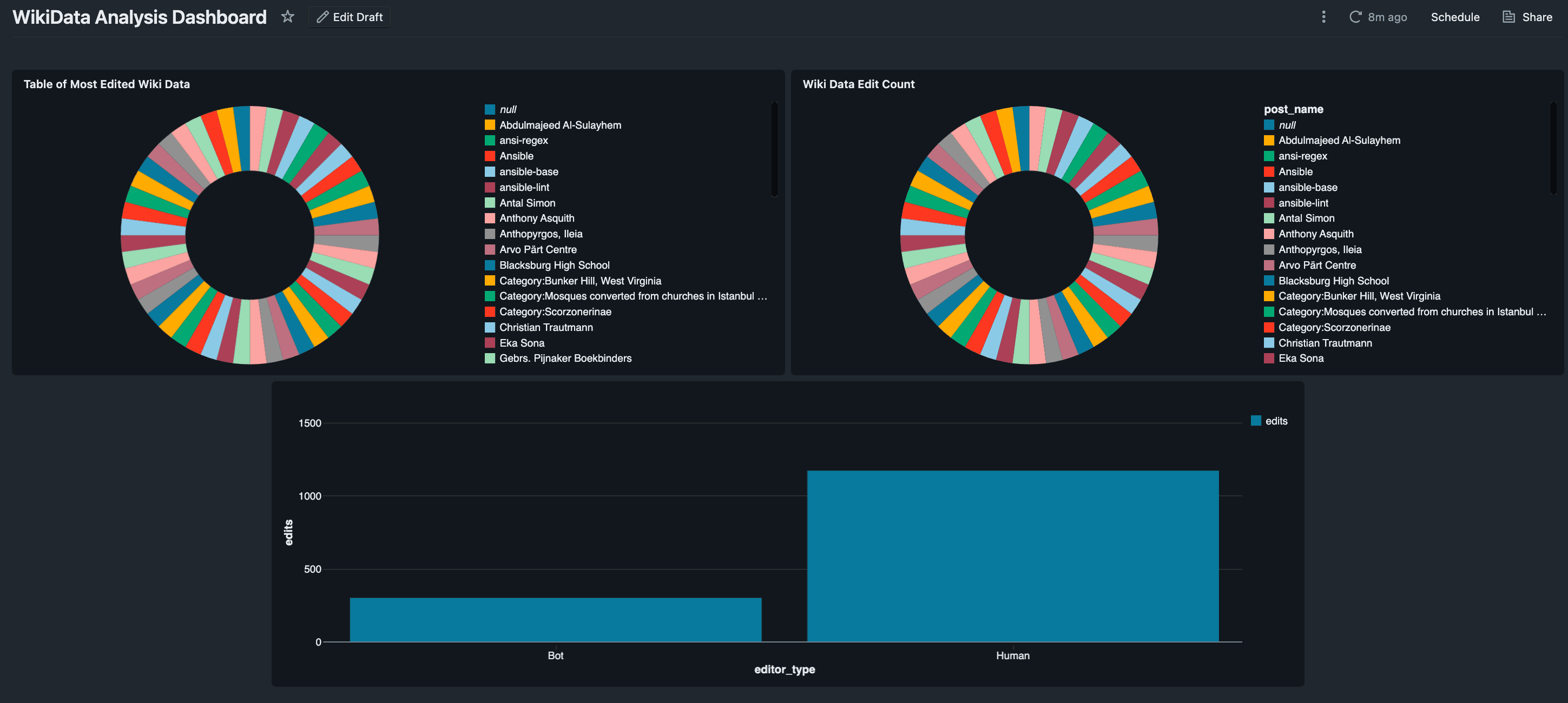
Live dashboard showing top edited WikiData entities, bot vs human contributions, and entity type distributions(Click to enlarge)
Enterprise Databricks Platform Access
Active Databricks Data Intelligence Platform subscription demonstrating enterprise-grade cloud infrastructure experience(Click to enlarge)
Implementation Highlights
Cloud Infrastructure
- AWS/Azure auth, IAM roles, workspace setup
- Secure S3/ADLS storage and networking
- CLI-driven deployment readiness
Streaming Ingestion
- Filters for wikidatawiki events
- Schema-defined micro-batch processing
- Resilient error handling
Enrichment Pipeline
- Q-ID extraction + API enrichment
- Pandas UDFs and request caching
- Human-readable labels and types
Analytics Dashboard
- Top updated items (Top 50)
- Bot vs human contribution mix
- Instance type distribution
Alignment to Senior Cloud Services Engineer
Direct Matches
- Azure/Cloud: Databricks (Azure-native capable) + cloud networking
- Terraform-ready: infra modeled for IaC rollout
- Azure Monitor: plan for metrics, alerts, logs
- Databricks: core of ingestion, curation, analytics
- Enterprise scale: streaming, resilient, modular
Responsibilities Addressed
- Design and improve cloud services and data pipelines
- Integrate systems and third‑party APIs (WikiData)
- Environment parity: sandbox → prod considerations
- Observability hooks for future Azure Monitor
Interview-Ready Deliverables
Key Artifacts
- Ingestion client:
- Curation logic:
- Dashboard queries:
- Table DDL:
Talking Points
- Real-time pipeline with curated Delta
- API enrichment and schema governance
- Analytics: top items, bot vs human, types
- Terraform + Azure Monitor next-step plan